Cipherome
(Deciphering Personal Genome)
The Cipherome is a project to
establish systematic infrastructures and develop computational methods
for interpreting personal genome variations.
In this project, we expect to evaluate the association between common disease and rare variant(s) through the mutational profile.
Especially, we will take a look into even 'private' variants from an individual and assess a combination of private mutations.
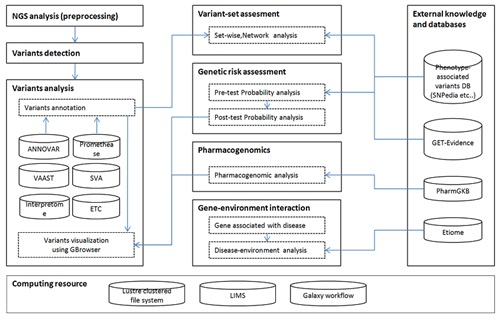
- Establishing systematic infrastructures for interpreting personal genome variations.
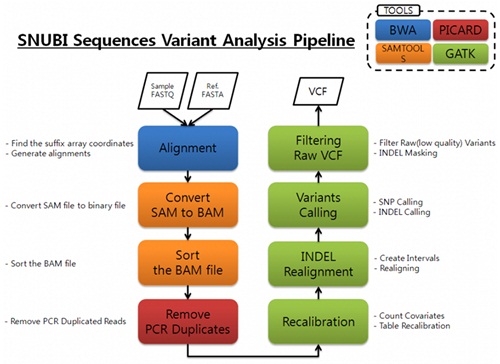
- Pipelining for sequence variant analysis.
- Analyzing the mutation profile on the Pan-omic scale.
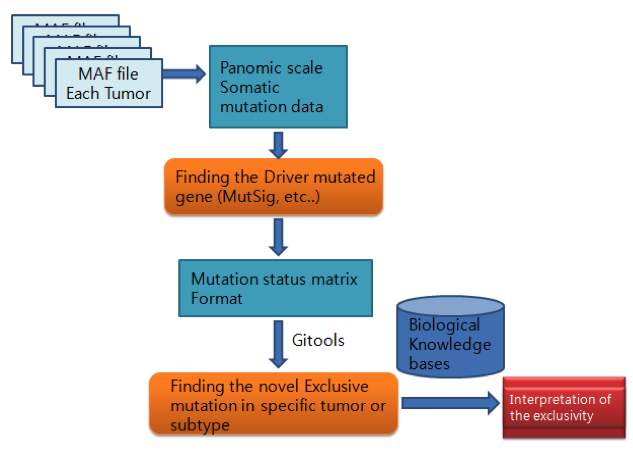
- Objectives
- Using the variety of publicly available TCGA mutation data of Pan-omic scales, Identifying the novel exclusive genes associated with a particular tumor type or subtype. Finally, interpret the somatic mutation profile in Pan-omic scale.
- Methods
- Data processing
- Extracting the non-synonymous mutation of the MAF files and generating the Pan-omic scale tumor MAF files.
- Conducting the basic data analysis
- Finding the driver mutation and exclusive mutation
- Finding the driver mutation using the existing tools ( MutSig, etc..)
- Novel exclusive mutation in specific mutation using the exclusive test and visualizing the mutation status
- Interpretation of the exclusivity
- Using the Biological knowledge databases (Pathway and functional based), Interpreting the result of tumor specific mutated gene
- Expected results
- Finding the mutation on Pan-omic scale mutation analysis, were exclusive and could not through existing data analysis is known in the study of tumor existing in subtype or tumor-specific. Through interpretation of it, which also affects the clinical treatment.
- Association between zygosity and the level of expression
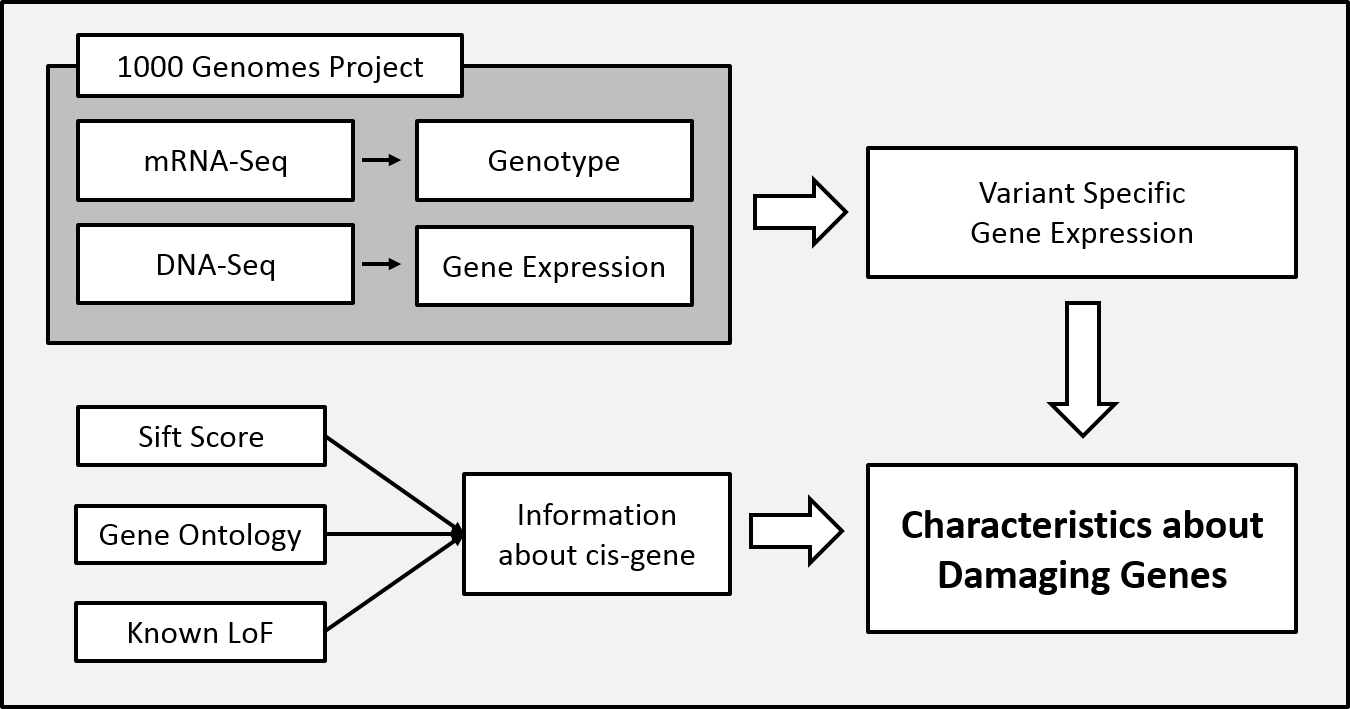
- Objectives
- Correlation between variants and gene expression
- How damaging variants affects cis-gene expression?
- Methods
- Integrating 1000 Genomes Projects mRNA-sequencing data and whole genomes sequencing data.
- Finding homo- and hetero- zygous varaints and their allele-specific expression.
- Using gene damaging scores like SIFT or PolyPhen to evaluate correlation between gene expression and allele-specific expression.
- Expected results
- Gene expression from allele with damaging varaints might be decreased.
- Assessment of rare germline mutations for cancer susceptibility with association study.
- Objectives
- The present study aims to develop and investigate predisposition patterns of rare germline mutations for hereditary cancer.
- Methods
- In order to achieve the goal, an association study will be performed on an aggregated rare germline variants and significant cancer risk alleles identified by cancer GWAS.
- Expected results
- I expect my results to identify rare variants that initiate hereditary cancer using association study by aggregating rare variants effects. That is, I believe that multiple rare germline variants across large region will greatly increase the power of contribution towards cancer by aggregating rare variants effects. Rare variants that have large effect are very rare since they are a failure result of purifying selection. As this is relatively new research area, this novel approach is a beginning of paradigm shift in association study using sequencing technologies.